Erkennen von
Schlüsselwörtern (DR,WH, ....)
Zahlen (allgemein: Datenkonstanten)
Syntaxrelevanten Sonderzeichen ( bis jetzt nur '[' und ']' )
Bezeichnern (wird im späteren Ablauf der Unterrichtsreihe abgehandelt)
Operatoren (wird im späteren Ablauf der Unterrichtsreihe abgehandelt)
Abspeichern dieser Einheiten (Token) in einer
Textdatei.
Statt einer Textdatei ist natürlich jede andere dynamische Datenstruktur
geeignet.
Der Scanner soll als endlicher Automat realisiert werden. (Welch Wunder, da wir uns ja nun lange genug mit endlichen Automaten beschäftigt haben). Das Eingabealphabet besteht hierbei aus (ASCII-)-Zeichen. Es ergibt sich recht offensichtlich folgender endlicher Automat:
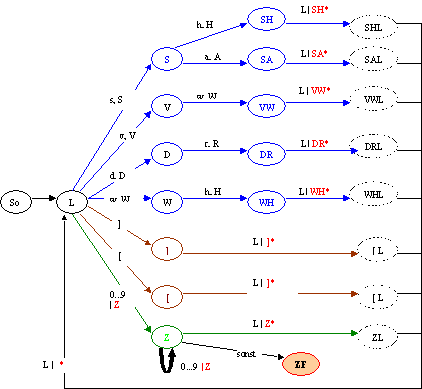
' L' bedeutet Leerzeichen, 'Z' meint die eingegebene Ziffer.
Wird im Zahlzustand keine Zahl und kein Leerzeichen eingegeben,
landet der Automat im Fehlerzustand ZF.
Alle anderen nicht angegebenen Zeichen führen wiederum in den Anfangszustand
Z0. Die Ausgaben des Scanners sind in rot
geschrieben. Das * stellt das Trennzeichen dar, mit
dem für den Parser nachher das Einlesen der Token erleichtert wird. Da wir die
Token in eine Textdatei schreiben, ist das Trennzeichen einfach der
Zeilenvorschub.
Die zur Verdeutlichung eingezeichneten gestrichelten Zustände werden bei diesem Automaten nicht benötigt. Denn durch Eingabe eines Leerzeichens (L) gelangt man wiederum in den Zustand L.
Im beiliegenden Delphi-Projekt sind Übergangs und Ausgabefunktion des Automaten durch die Funktion
function TForm1.f(z: TScanZustand; e:char):TScanZustand;
realisiert worden. Es handelt sich wie auch schon bei früheren Automaten um
einfache geschachtelte Verzweigungen:
Anfangszustand Leerzeichenzustd Zahlzustand wird im Zahlzustand keine Zahl und kein Leerzeichen eingegeben, landet der Automat im Fehlerzustand Zustand nach 'S' Zustand nach 'D' Zustand nach 'V' Zustand nach 'W' Zustand nach Klammer auf Zustand nach Klammer Zu Zustand nach 'S' gefolgt von 'A' Zustand nach 'S' gefolgt von 'H' Zustand nach 'D' gefolgt von 'R' Zustand nach 'V' gefolgt von 'W' Zustand nach 'W' gefolgt von 'H' |
Programmcode:
function TForm1.f(z: TScanZustand; e:char):TScanZustand;
begin
case z of
z0: case e of
' ': begin
f := L;
end
else
f:= z0;
end; (* of case e of*)
L: case e of
' ': begin
f := L;
end;
'[':begin
f := KA
end;
']':begin
f := KZ
end;
'v','V': begin
f := V;
end;
'd','D': begin
f := D;
end;
's','S': begin
f := S;
end;
'w','W': begin
f := W;
end;
'0'..'9': begin
f := zz;
write(tokenfile,e);
end;
else f := z0;
end;(* of case e of L*)
ZZ: case e of '0'..'9': begin
f:= zz;
write(tokenfile,e)
end;
' ': begin
f:= L;
writeln(tokenfile,'')
end;
else begin
f := zf;
writeln(tokenfile,'');
end;
end;(* of case e of Z*)
S: case e of
' ': begin
f := L;
end;
'a','A': begin
f := SA;
end;
'h','H': begin
f := SH;
end;
else f := z0;
end;(* of case e of S*)
D: case e of
' ': begin
f := L;
end;
'r','R': begin
f := DR;
end;
else f := z0;
end;(* of case e of *)
V: case e of
' ': begin
f := L;
end;
'w','W': begin
f := VW;
end;
else f := z0;
end;(* of case e of V*)
W: case e of
' ': begin
f := L;
end;
'h','H': begin
f := WH;
end;
else f := z0;
end;(* of case e of W*)
KA: case e of
' ': begin
writeln(tokenfile,'[');
f := L;
end;
else f := z0;
end;(* of case e of KA*)
KZ: case e of
' ': begin
writeln(tokenfile,']');
f := L;
end;
else f := z0;
end;(* of case e of KZ*)
SA: case e of ' ': begin
f := L;
writeln(tokenfile,'SA');
end;
else f := z0;
end;(* of case e of SA*)
SH: case e of ' ': begin
f := L;
writeln(tokenfile,'SH');
end;
else f := z0;
end;(* of case e of SH*)
DR: case e of ' ': begin
f := L;
writeln(tokenfile,'DR');
end;
else f := z0;
end;(* of case e of DR*)
VW: case e of ' ': begin
f := L;
writeln(tokenfile,'VW');
end;
else f := z0;
end;(* of case e of *)
WH: case e of ' ': begin
f := L;
writeln(tokenfile,'WH');
end;
else f := z0;
end;(* of case e of *)
end (* of case Z of*)
end;
|
| Zur
nächsten Seite
|
| © 2001 LK 13 If und G. Kubitz | Hannah-Arendt-Gymnasium, Lengerich |